
 13867128415
13867128415
高光谱识别真假甘草分类模型
高光谱分类模型是基于高光谱遥感技术发展而来的机器学习 / 深度学习模型,核心目标是通过分析高光谱图像中数百个连续、窄波段的光谱信息,实现对地表地物(如植被、土壤、水体、矿物、人工建筑等)的精细分类与识别。与传统多光谱遥感(仅几个至几十个离散波段)相比,高光谱数据能捕捉地物独特的 “光谱指纹”,使模型具备更强的区分能力(例如区分不同种类的作物、识别矿物成分、检测植被病虫害等)。
项目内容
高光谱识别真假甘草分类模型
一、检测目的和依据
- 使用高光谱技术,采集中药材中真甘草与假甘草光谱数据,通过建模分析实现高光谱技术无损检测甘草真假。
二、样品类别及数量
甘草样本:
- 中药材真甘草若干条;
- 假甘草若干条;
三、检测设备和方法
检测设备
1. 400-1000nm高光谱相机
2. 高光谱采集暗箱
3. 黑色托盘(低反射率背景)
4. 辅助材料:标签(用于标记真假甘草)
采集方式
1、训练集样品摆放规则:
中药材甘草:将样品中药材甘草按如图所示摆放,使用标签标记好甘草的真假。

2、验证集数据采集方式
将真假甘草摆放在托盘,标记真假的标签放在了甘草样品下面放着

四、采集与分析结果
1. 数据提供
提供数据格式,每个样品数据包含如下6个格式文件:
- 样本400-1000nm原始数据(包含 .dat、.hdr格式)
- 样本400-1000nm反射率数据(包含 .dat、.hdr格式)
- 样本400-1000nm高光谱图像(.png格式)
2. 数据预处理
1、使用打标工具,甘草样本进行打标,结果图如下
训练集:

验证集:


3.光谱反射率提取
真甘草(C1)和假甘草(C2)的反射率平均光谱图
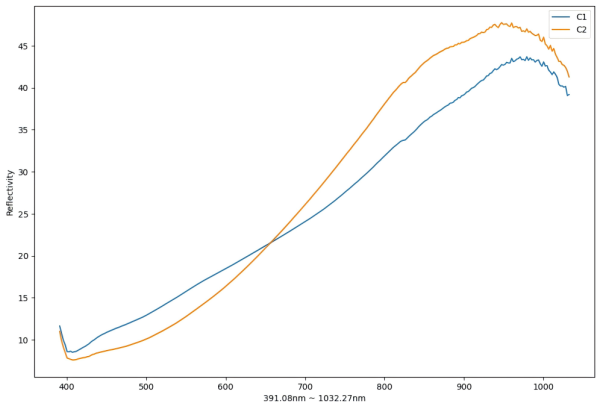
根据反射率曲线可以看出,真假甘草反射率存在较大差异
数据预处理
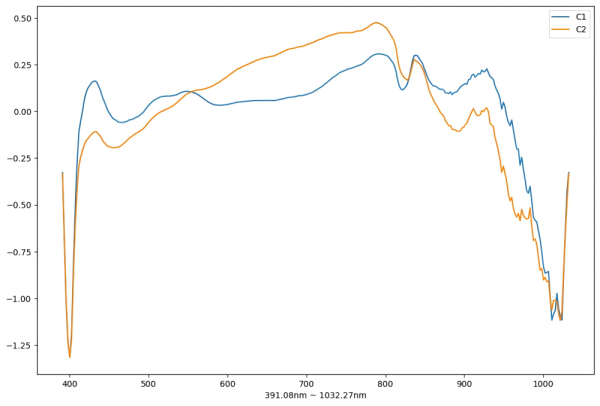
为了进一步消除噪声, 消除位置影响, 提升特征显著性, 我们实验了多种预处理方法的组合, 最终选用效果最好的预处理方式 SGD1 + SNV 对原始进行处理.预处理后的 C1 和 C2 数据如下图所示:
特征分析
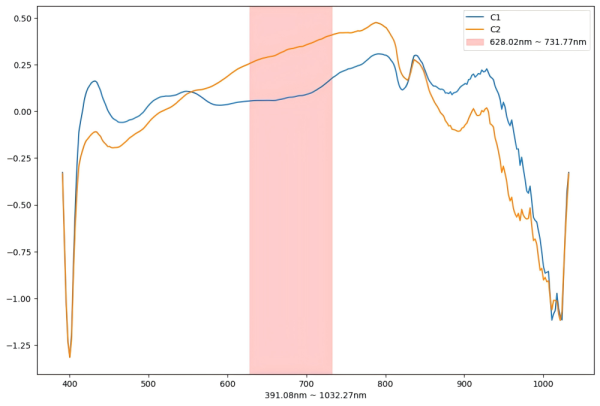
根据波段和分组的相关性分析, 获得分组相关性最高的前 50 个波段位于下图中红色矩形区域
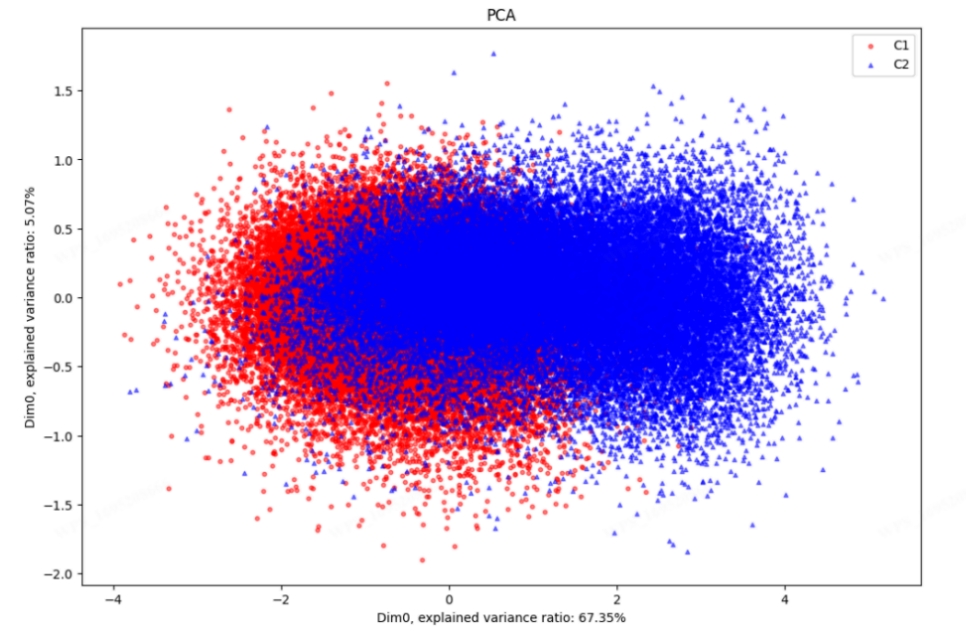
相关性最高的前 50 个 波段的 PCA 图像
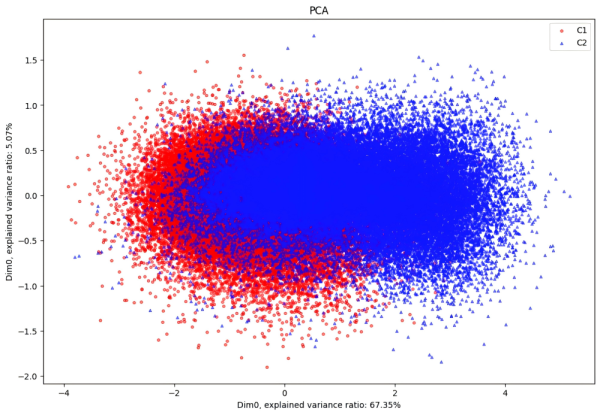
依据以上条件我们可以认为:真甘草(C1)和假甘草(C2) 光谱数据在 628.02nm 到 731.77nm 之间存在较为明显的差异
模型训练
模型采用我们自有的针对高光谱数据研发的深度学习模型架构,更容易捕获特征与标签之间的非线性关系。
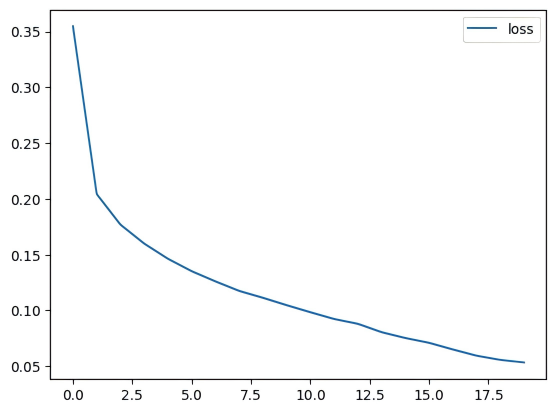
训练数据使用上文中的 训练集01,训练 20 个 Epoch,每个 Epoch 结束后使用验证集进行一次评估
训练过程中损失下降情况如下图所示:
训练后在训练集上的推理结果:
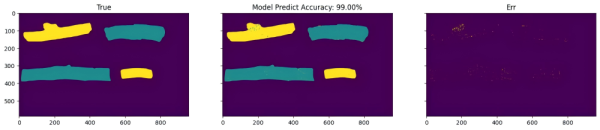
对比基线模型(KNN)准确率
验证集01评价结果
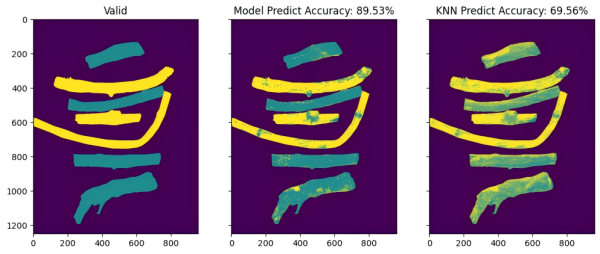
验证集02评价结果
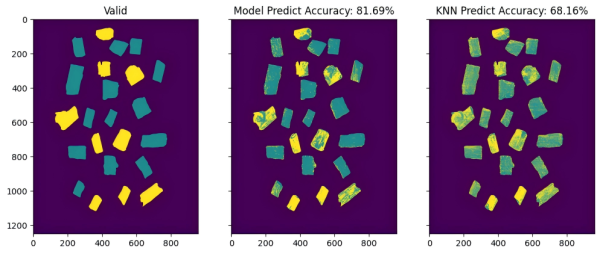
结果评价:
- 对比训练集, 模型能力有所下降, 但准确率依然高于基线模型 10% ~ 20%
- 模型能力下降的主要原因是训练样本不够, 使用更多样本进行训练可以有效提升模型泛化能力
- 经过后处理, 即: 在空间维度对标签做平滑处理 + 对单个样本使用置信度 (样本中标记为真的光谱数量 / 样本中所有光谱的数量) > 0.8 可以实现对验证集中样本识别做到 100% 准确率
 首页
首页
 数据采集
数据采集
 数据处理
数据处理
 联系我们
联系我们