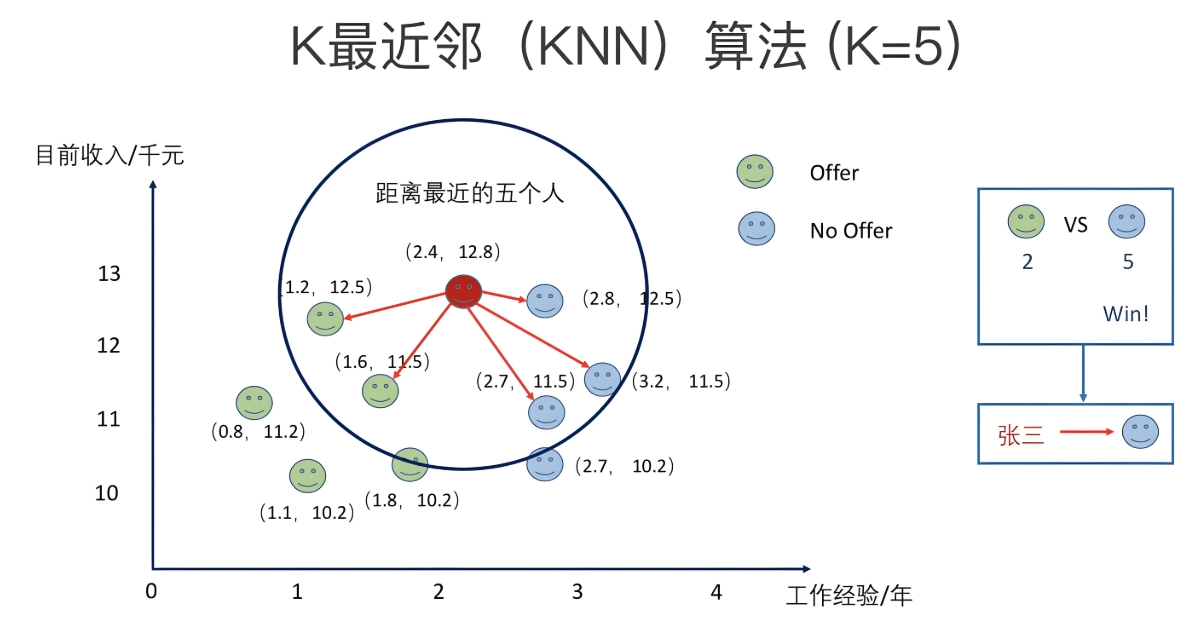
k-NN 不提前训练复杂模型参数,而是将训练数据直接作为 “知识库”,预测时仅通过距离计算和邻居投票 / 平均得出结果,核心步骤分两步:
距离越小,代表两个样本越相似。常用距离度量方式有 3 种:
- 欧氏距离(Euclidean Distance):最常用,适用于连续特征,计算两点在空间中的直线距离,公式为:\(d(x,y) = \sqrt{\sum_{i=1}^n (x_i - y_i)^2}\)其中\(x、y\)是两个样本,n是特征数量,\(x_i、y_i\)是样本在第i个特征上的取值。
- 曼哈顿距离(Manhattan Distance):适用于高维特征或特征值为整数的场景,计算两点在各维度上的绝对差值之和,公式为:\(d(x,y) = \sum_{i=1}^n |x_i - y_i|\)
- 余弦相似度(Cosine Similarity):适用于文本、图像等高维稀疏特征,衡量两个样本向量的夹角(值越接近 1,相似度越高),公式为:\(\cos\theta = \frac{x \cdot y}{||x|| \cdot ||y||}\)
- 选 k 值:设定超参数 k(需人为指定,如 3、5、7),表示要参考的 “邻居” 数量。
- 找邻居:计算待预测样本与所有训练样本的距离,筛选出距离最小的 k 个样本(即 k 近邻)。
- 做预测:
- 分类任务:对 k 个邻居的类别进行 “投票”,得票最多的类别即为待预测样本的类别。
- 回归任务:计算 k 个邻居的数值 “平均值”(或加权平均值,距离越近权重越大),作为待预测样本的结果。
k-NN 的性能几乎完全依赖两个超参数,需重点调优:
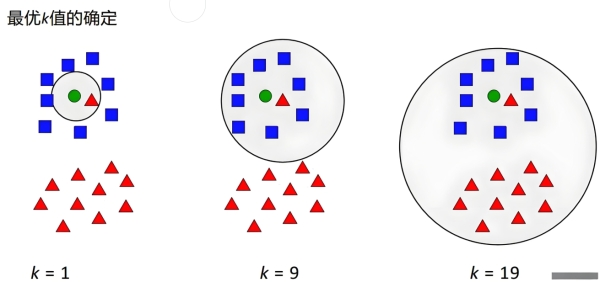
k 值决定了模型的 “局部性” 与 “稳定性”,对结果影响极大:
- k 值过小(如 k=1):模型仅依赖单个最近邻,易受噪声、异常值干扰,导致过拟合(预测结果波动大)。
- k 值过大(如 k = 样本总数):模型参考所有训练样本,相当于 “全局平均”,忽略局部特征,导致欠拟合(预测结果过于笼统)。
- 常用取值:通常选择奇数(如 3、5、7、9),避免投票平局;实际需通过交叉验证(如 5 折交叉验证)筛选最优 k 值。
不同距离适用于不同数据场景,选错会直接降低模型精度:
- 连续特征(如身高、体重、房价):优先用欧氏距离。
- 高维稀疏特征(如文本的词频向量、图像的像素向量):优先用余弦相似度(避免高维空间中欧氏距离失效)。
- 整数特征或网格数据(如经纬度、用户 ID 对应的等级):可用曼哈顿距离。
k-NN 对特征尺度极其敏感(如 “身高(厘米)” 和 “体重(千克)”,前者数值范围远大于后者,会导致距离计算被身高主导),因此必须先做数据标准化 / 归一化,常用两种方式:
- 标准化(Z-Score Normalization):将特征转换为均值为 0、标准差为 1 的分布,公式为:\(x' = \frac{x - \mu}{\sigma}\)其中\(\mu\)是特征均值,\(\sigma\)是特征标准差,适用于大部分连续特征场景。
- 归一化(Min-Max Normalization):将特征压缩到 [0,1] 或 [-1,1] 区间,公式为:\(x' = \frac{x - x_{min}}{x_{max} - x_{min}}\)其中\(x_{min}\)是特征最小值,\(x_{max}\)是特征最大值,适用于特征取值范围明确的场景(如像素值 0-255)。
- 实现简单:无需训练模型参数,逻辑直观,代码易编写(仅需距离计算和投票 / 平均)。
- 适应性强:可处理分类、回归任务,无需假设数据分布(如线性模型需假设数据线性可分,k-NN 无此要求)。
- 对新数据友好:新增训练样本时,无需重新训练模型(仅需将新样本加入 “知识库”),适合动态数据场景。
- 计算效率低:预测时需与所有训练样本计算距离,当训练样本量极大(如百万级、千万级)时,速度极慢(可通过 “KD 树”“Ball 树” 优化,但仍不如线性模型快)。
- 内存消耗大:需存储全部训练样本,样本量过大时内存压力大。
- 对高维数据不友好:高维空间中 “距离” 的区分度会下降(即 “维度灾难”),导致邻居选择不准确,预测精度降低。
- 对不平衡数据敏感:若某类样本占比极高(如正例 90%,负例 10%),k 个邻居中大概率多为正例,易导致负例预测错误(需通过样本加权或过采样 / 欠采样优化)。
k-NN 适合小规模数据、低维特征的场景,常见应用包括:
- 分类任务:手写数字识别(早期经典场景)、推荐系统(如 “找相似用户推荐商品”)、简单图像分类(如区分猫和狗的低分辨率图像)。
- 回归任务:房价初步预测(特征少、样本量小时)、用户消费金额预测(基于相似用户的消费习惯)。
- 其他:异常值检测(如找出与大部分样本距离过远的 “异常用户”“异常交易”)。
- Python:
scikit-learn:sklearn.neighbors.KNeighborsClassifier(分类)、KNeighborsRegressor(回归),支持欧氏距离、曼哈顿距离、余弦相似度,且可通过algorithm参数选择 “brute(暴力计算)”“kd_tree”“ball_tree” 优化效率。numpy:可手动实现欧氏距离、投票逻辑(适合学习原理时使用)。
- R:
class包中的knn()函数(经典实现,仅支持分类)。
为更清晰理解 k-NN 的定位,以下对比其与线性回归、随机森林的核心差异:

 13867128415
13867128415
 首页
首页
 数据采集
数据采集
 数据处理
数据处理
 联系我们
联系我们