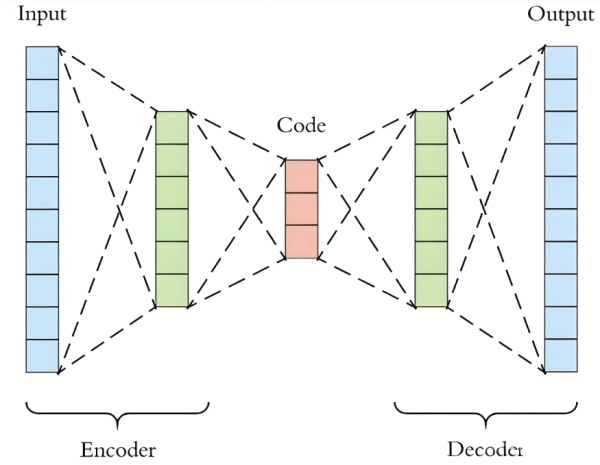
AE 是最经典的无监督特征学习模型,结构上分为 “编码器” 和 “解码器” 两部分,目标是让重构后的输出尽可能接近原始输入。
AE 的网络结构呈对称分布,通常由全连接层、卷积层(处理图像)或循环层(处理序列)构成,核心流程分两步:
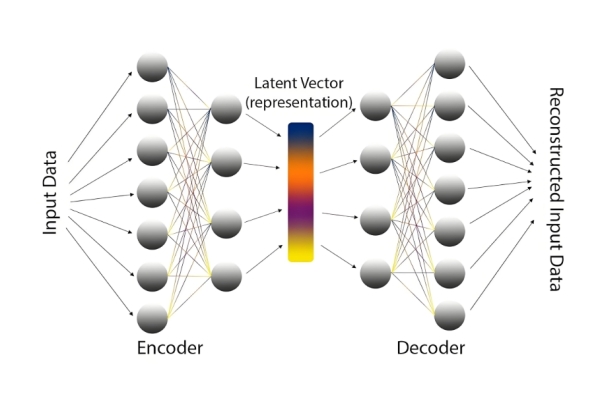
编码(Encoder):将高维原始数据
x(如 28×28 的手写数字图像,维度 784)映射到低维 latent 向量
z(如维度 32),捕捉数据的核心特征。
数学表达:
\(z = f_\theta(x)\),其中
\(\theta\)是编码器的参数(权重、偏置),
f通常是 “线性层 + 激活函数(如 ReLU)” 的组合。
解码(Decoder):将低维 latent 向量
z反向映射回高维重构数据
\(\hat{x}\),尽量还原原始数据的细节。
数学表达:
\(\hat{x} = g_\phi(z)\),其中
\(\phi\)是解码器的参数,
g的结构与编码器对称(如编码器用 “784→32”,解码器则用 “32→784”),输出层激活函数根据数据类型选择(如图像用 sigmoid 将像素值归一到 [0,1])。
<img src="https://i.imgur.com/8Z6y0qc.png" alt="自编码器结构示意图" width="400">
(左:原始数据;中:Encoder将x压缩为z;右:Decoder将z重构为
\(\hat{x}\))
AE 的损失函数为重构损失,衡量原始输入x与重构输出\(\hat{x}\)的差异,常用两种形式:
- 适用于连续数据(如灰度图像、数值序列):均方误差(MSE)\(\mathcal{L}_{MSE} = \frac{1}{N}\sum_{i=1}^N ||x_i - \hat{x}_i||^2\)
- 适用于离散数据(如二值图像、文本 one-hot 向量):交叉熵损失(Cross-Entropy)\(\mathcal{L}_{CE} = -\frac{1}{N}\sum_{i=1}^N \sum_{j=1}^D [x_{i,j}\log\hat{x}_{i,j} + (1-x_{i,j})\log(1-\hat{x}_{i,j})]\)其中N是样本数,D是数据维度,\(x_{i,j}\)是第i个样本第j维的原始值,\(\hat{x}_{i,j}\)是对应的重构值。
- 稀疏自编码器(Sparse AE):在损失中加入稀疏正则项(如 L1 正则),强制 latent 向量多数元素为 0,仅用少数维度表示核心特征,增强特征的区分度。
- 卷积自编码器(Convolutional AE,CAE):用卷积层(Encoder)和反卷积层(Decoder)替代全连接层,专门处理图像数据,能更好保留空间局部特征(如边缘、纹理)。
- 降噪自编码器(Denoising AE,DAE):在原始输入x中添加噪声(如高斯噪声、随机遮挡),训练模型从噪声数据中重构出干净数据,增强模型的鲁棒性和特征提取能力。
AE 的 latent 向量z是 “确定性” 的 —— 每个x对应唯一的z,且 latent 空间可能不连续(不同类别的z混杂分布)。这导致:
- 无法通过 “随机采样z” 生成有意义的新数据(采样的z可能对应无实际意义的重构结果);
- 难以用z进行数据插值(如从 “猫” 的z插值到 “狗” 的z,中间结果可能是混乱的)。
VAE 在 AE 的基础上引入概率分布假设,将 latent 向量z建模为随机变量(而非确定性向量),使 latent 空间连续且可解释,从而具备可控的生成能力。
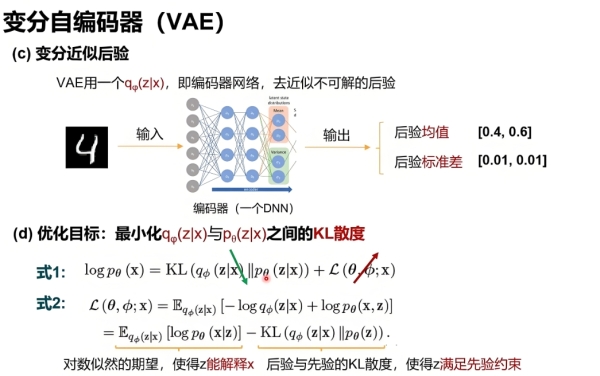
VAE 的核心创新是:假设 “所有原始数据x均由某个潜在概率分布\(p(z)\)生成”,模型需同时学习 “z的分布” 和 “从z生成x的映射”,具体通过两个关键步骤实现:
- 编码端(推断网络):不直接输出z,而是输出z的概率分布参数(如高斯分布的均值\(\mu\)和方差\(\sigma^2\)),表示 “x对应z的不确定性”。
- 解码端(生成网络):从编码端输出的分布中随机采样z,再用z重构x,通过 “重参数化技巧” 解决采样过程的梯度不可导问题。
VAE 的结构比 AE 更复杂,需同时优化 “重构精度” 和 “分布匹配度”:
步骤 1:编码(推断z的分布)编码器输入
x,输出
z服从的高斯分布参数:
\(\mu(x) = f_\theta(x)\),
\(\log\sigma^2(x) = h_\theta(x)\)(用
\(\log\sigma^2\)避免方差为负)。
此时
z的后验分布为:
\(q_\theta(z|x) = \mathcal{N}(z; \mu(x), \sigma^2(x)I)\)(
I是单位矩阵)。
步骤 2:重参数化采样(解决梯度问题)直接从
\(q_\theta(z|x)\)采样
z会导致梯度无法回传(采样是随机操作,不可导)。VAE 通过 “重参数化” 将采样过程拆解为:
\(z = \mu(x) + \sigma(x) \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)\)其中
\(\epsilon\)是从标准正态分布中采样的随机噪声,此时
z的随机性由
\(\epsilon\)决定,
\(\mu(x)\)和
\(\sigma(x)\)可通过梯度下降更新。
步骤 3:解码(从z生成x)解码器输入采样得到的
z,输出
x的重构分布(如连续数据用高斯分布,离散数据用伯努利分布),即
\(p_\phi(x|z) = \mathcal{N}(x; \hat{x}, \sigma^2I)\)(或伯努利分布),其中
\(\hat{x} = g_\phi(z)\)是重构均值。
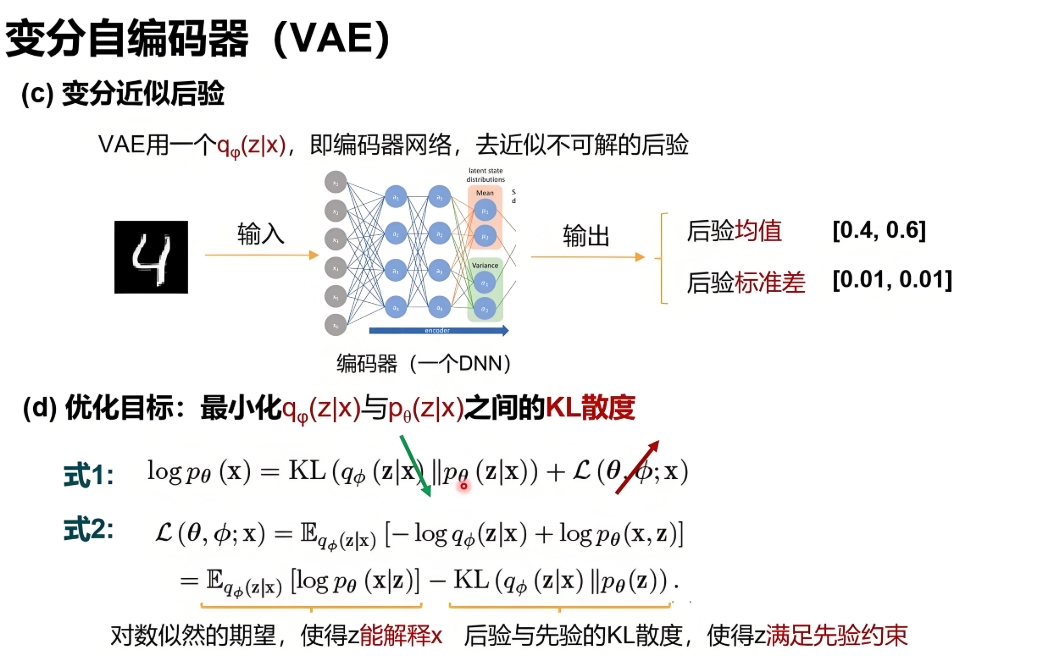
VAE 的损失函数不是单纯的重构损失,而是证据下界(Evidence Lower Bound,ELBO),包含两部分:
- 重构损失(Reconstruction Loss):与 AE 类似,衡量x与\(\hat{x}\)的差异,确保模型能从z还原数据。
- KL 散度(KL Divergence):衡量 “编码端的后验分布\(q_\theta(z|x)\)” 与 “预设的先验分布\(p(z)\)(通常设为标准正态分布\(\mathcal{N}(0,I)\))” 的差异,强制z的分布接近先验,使 latent 空间连续且可解释。
ELBO 的数学表达式(以连续数据为例):
\(\mathcal{L}_{ELBO} = \mathbb{E}_{q_\theta(z|x)}[\log p_\phi(x|z)] - KL(q_\theta(z|x) || p(z))\)- 第一项:重构损失的期望(最大化此项,让x与\(\hat{x}\)更接近);
- 第二项:KL 散度(最小化此项,让\(q_\theta(z|x)\)接近\(p(z)\))。
由于 VAE 的 latent 空间是连续且接近标准正态分布的,可通过以下方式生成新数据:
- 从先验分布\(p(z) = \mathcal{N}(0,I)\)中随机采样一个 latent 向量z;
- 将z输入解码器\(g_\phi(z)\),得到重构输出\(\hat{x}\)—— 此\(\hat{x}\)即为模型生成的新数据(如随机采样z生成手写数字、人脸图像)。
此外,VAE 还支持数据插值(如在 “猫” 的\(z_1\)和 “狗” 的\(z_2\)之间线性插值,生成从猫到狗的过渡图像)
AE 的应用:
- 特征提取:将 AE 的编码器作为预训练模型,为分类、回归任务提供低维特征;
- 数据降维:替代 PCA,处理非线性数据的降维(如将高维图像降维后可视化);
- 异常检测:通过计算 “x与\(\hat{x}\)的重构误差”,误差大的样本判定为异常(如工业设备故障检测、信用卡欺诈识别)。
VAE 的应用:
- 图像生成:生成手写数字(MNIST)、人脸(CelebA)、风景等图像;
- 文本生成:将文本编码为 latent 向量,采样后解码生成新句子;
- 风格迁移:编辑 latent 向量的特定维度,改变生成数据的风格(如将 “素描脸” 转为 “彩色脸”)。

 13867128415
13867128415
 首页
首页
 数据采集
数据采集
 数据处理
数据处理
 联系我们
联系我们