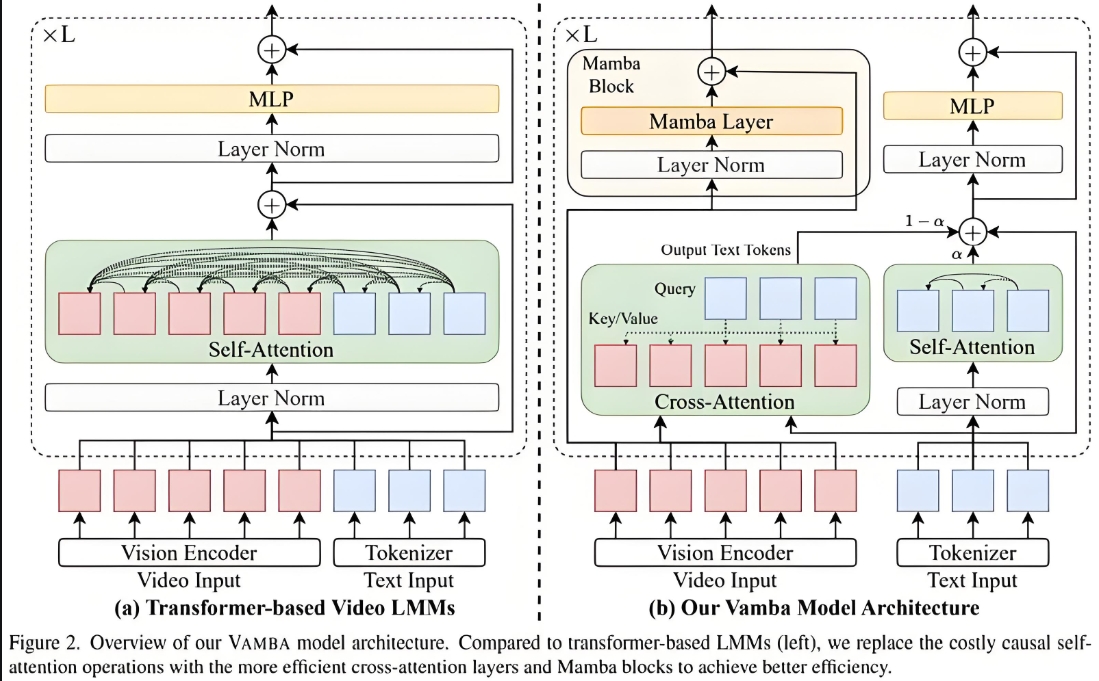
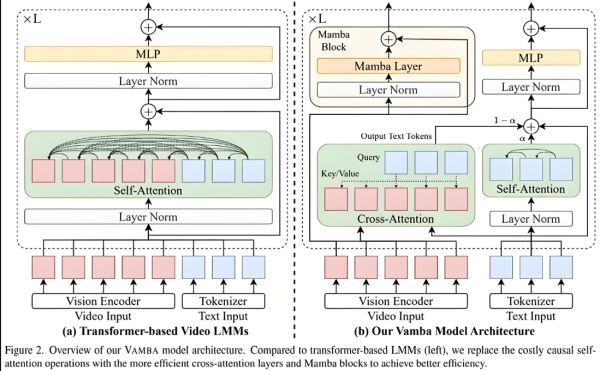
该混合模型本质是 “两步串联结构”,而非简单的并行融合。SVM(支持向量机)或 RF(随机森林)负责 “预处理”,LSTM 负责 “核心预测”,具体分工如下:
- 第一步:SVM/RF 做特征工程处理原始数据中的非时序特征(如用户性别、产品类别等),或从高维特征中筛选关键信息。
- 对 SVM:通过核函数映射,提取对分类 / 回归任务贡献度高的特征,剔除冗余噪声。
- 对 RF:通过决策树投票,计算特征重要性,保留 Top-N 关键特征,降低数据维度。
- 第二步:LSTM 做时序预测将 SVM/RF 筛选后的 “关键特征” 与原始数据中的 “时序特征”(如每日销量、每小时温度等)结合,输入 LSTM 网络。LSTM 通过门控机制(输入门、遗忘门、输出门),捕捉时序数据的长期依赖关系,最终输出预测结果。
两种组合的核心区别在于 “特征筛选方式”,需根据数据特点选择,具体对比如下:
该混合模型的优势在 “多特征 + 时序” 类任务中尤为明显,常见场景包括:
- 金融预测:用 RF 筛选宏观经济指标(GDP、利率),再用 LSTM 预测股票价格、汇率走势。
- 工业故障预警:用 SVM 提取设备振动、温度等关键特征,再用 LSTM 预测设备故障发生时间。
- 用户行为预测:用 RF 筛选用户年龄、消费习惯等特征,再用 LSTM 预测用户未来的购买时序。
- 数据预处理
- 拆分数据为 “时序特征”(如时间序列的历史值)和 “静态特征”(如用户属性)。
- 对缺失值、异常值进行处理,对特征做标准化 / 归一化。
- RF 特征筛选
- 用静态特征 + 部分时序特征训练 RF 模型,输出 “特征重要性排名”。
- 保留重要性 Top-5~Top-20 的特征(根据数据维度调整),形成 “筛选后特征集”。
- LSTM 模型训练
- 将 “筛选后特征集” 与原始时序特征拼接,构建 LSTM 的输入序列(需满足 LSTM 的 [样本数,时间步,特征数] 格式)。
- 搭建 LSTM 网络(含输入层、1~3 层 LSTM 层、全连接层、输出层),用训练集训练,验证集调参(如时间步、隐藏层节点数)。
- 模型评估与优化
- 用测试集验证模型性能,常用指标包括 MAE(平均绝对误差)、RMSE(均方根误差)、准确率(分类任务)。
- 若过拟合,可在 LSTM 层后加 Dropout 层;若欠拟合,可增加 LSTM 层数或扩大特征筛选范围。

 13867128415
13867128415
 首页
首页
 数据采集
数据采集
 数据处理
数据处理
 联系我们
联系我们