
 13867128415
13867128415


高光谱分选机案例:
使用高光谱技术区分真假甘草的可行性分析报告
实验结论
1. 使用高光谱数据建模训练后 , 能准确区分真假甘草
2. 对于单个光谱模型识别的准确能达到 80% 以上 , 对于单个样本 , 通过适当的后处理能做到100% 识别准确率
3. 由于现阶段实验样本, 模型能力任有较大的提升空间
实验过程 1数据采集 2采集方式
使用 400 ~ 1000 纳米波段高光谱相机分别采集多组数据 , 并对所有数据进行 FFC 校正 和暗电流校正 , 目的是去除传感器暗电流噪声以及消除不同位置光照条件不一致导致的光谱差异 , 保存采集到的反射率数据 .
数据集预览
预览图 | 标签图:C1- 真 ,C2 假 | 遮罩:绿色为真 ,红色为假 | |
训练集01 |
|
|
|
验证集01 |
|
|
|
验证集02 |
|
|
|









![]()
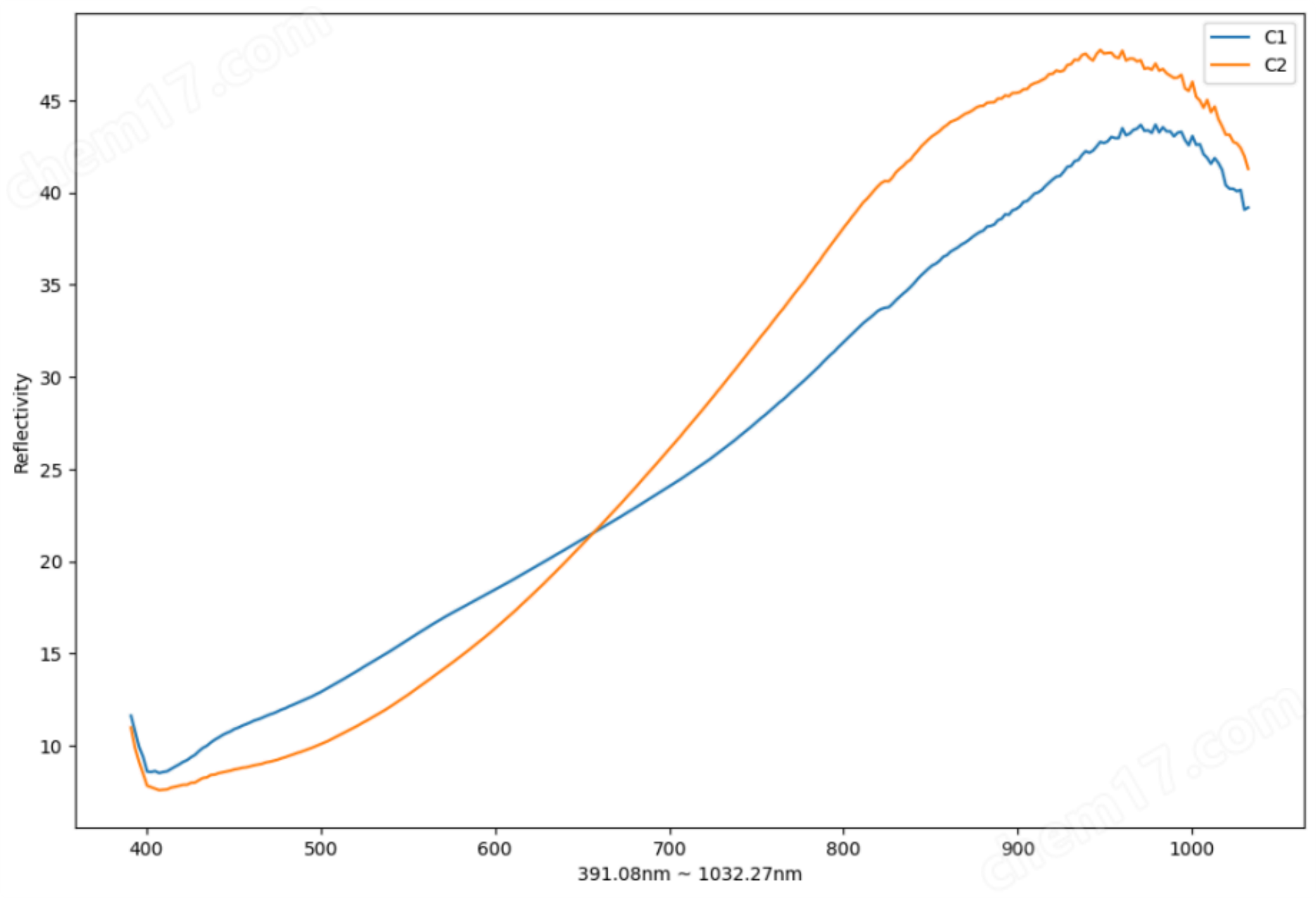
原始光谱分析
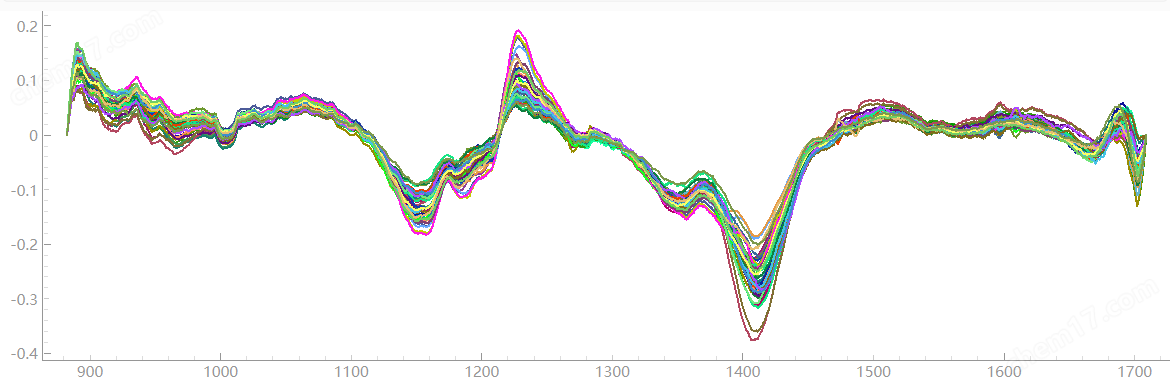
真甘草(C1)和假甘草(C2)的原始平均光谱图像

根据该图像可以看出 , C1 和C2 两条光谱之间存在较大差异
数据预处理
为了进一步消除噪声 , 消除位置影响 , 提升特征显著性 , 我们实验了多种预处理方法的组合 , 最终选用的预处理方式 SGD1+ SNV 对原始进行处理 . 预处理后的 C1 和C2 数据如下图所⽰ :

特征分析
根据波段和分组的相关性分析 , 获得分组相关性最高的前 50 个波段位于下图中红色矩形区域

相关性最高的前 50 个 波段的 PCA 图像

依据以上条件我们可以认为 : 真甘草(C1)和假甘草(C2) 光谱数据在 628.02nm 到731.77nm之间存在较为明显的差异
模型训练
模型采用我们自有的针对高光谱数据研发的深度学习模型架构 , 更容易捕获特征与标签之间的非线性关系 .
训练数据使用上文中的训练集01, 训练 20 个 Epoch, 每个 Epoch 结束后使用验证集进行一次评估
训练过程中损失下降情况如下图所⽰ :

训练后在训练集上的推理结果 :
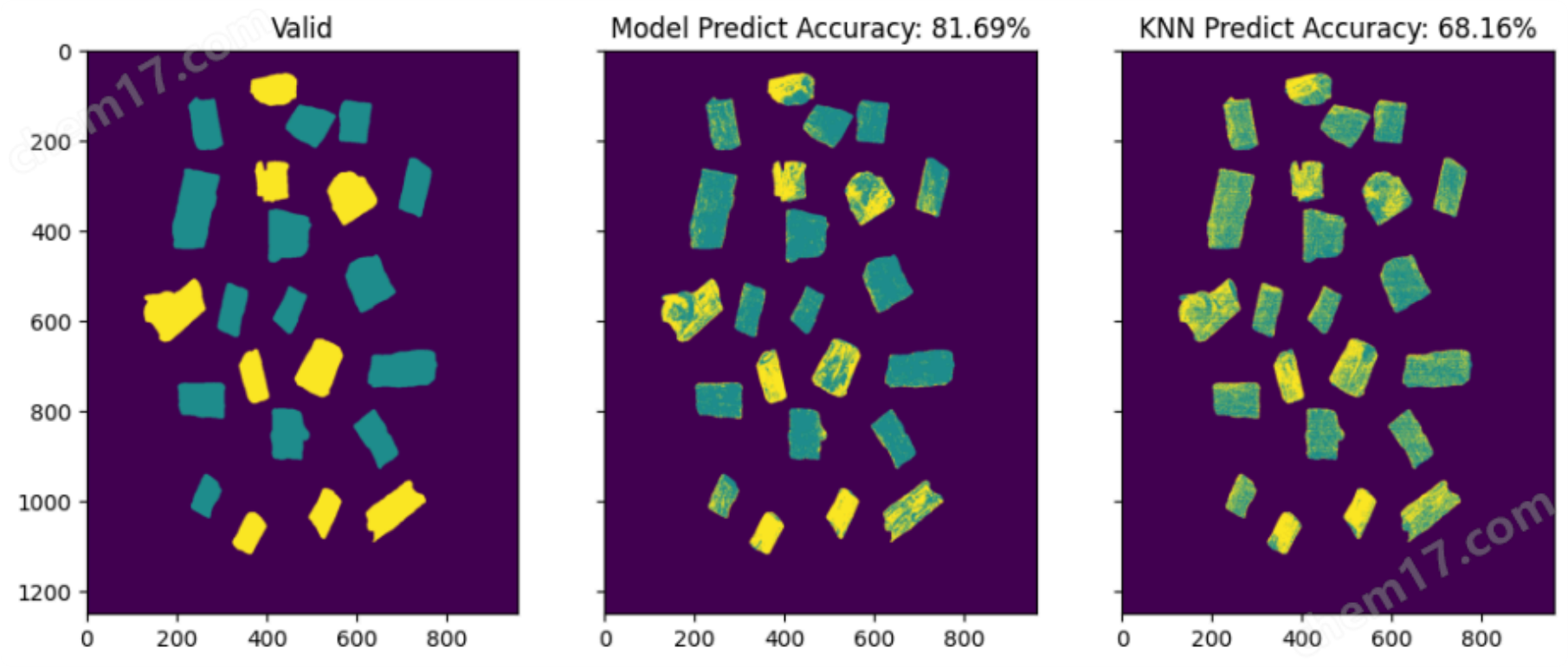
对比基线模型(KNN)准确率 :
评估结果 | |
验证集01 |
|
验证集02 |
|

![]()
模型验证结果
• 对比训练集 , 模型能力有所下降 , 但准确率依然高于基线模型 10% ~ 20%
• 模型能力下降的主要原因是训练样本不够 , 使用更多样本进行训练可以有效提升模型泛化能⼒
• 经过后处理 , 即 : 在空间维度对标签做平滑处理 + 对单个样本使用置信度 (样本中标记为真的光谱数量 / 样本中所有光谱的数量) > 0.8 ,可以实现对验证集中样本识别做到 100% 准确率。
火腿产地溯源分析
实验目的
使用 900 - 1700nm 高光谱数据区分不同种类的火腿
实验过程
数据采集
使用 900 - 1700nm 高光谱相机, 采集三种火腿样本的光谱数据. 三种火腿样本分别为: XW(宣威火腿), PX(盘县火腿), WN(威宁火腿)
采集环境: 使用卤素灯光源, 在暗箱环境中采集, 排除外部环境干扰
积分时间: 20 毫秒
采集数量: 每 2 片相同种类的样本为一组, 每张图像放 3 组不同的种类, 共采集 4 张图像
数据标注
文件名 | 标注情况 |
混 01 |
|
混 02 |
|
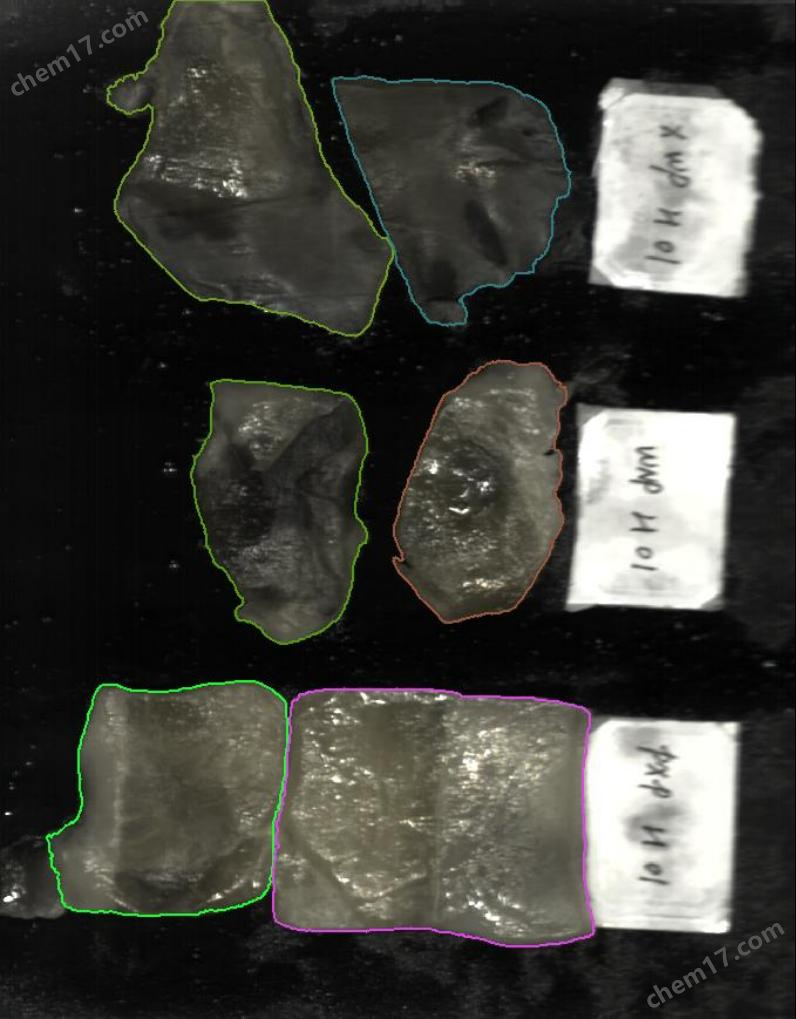
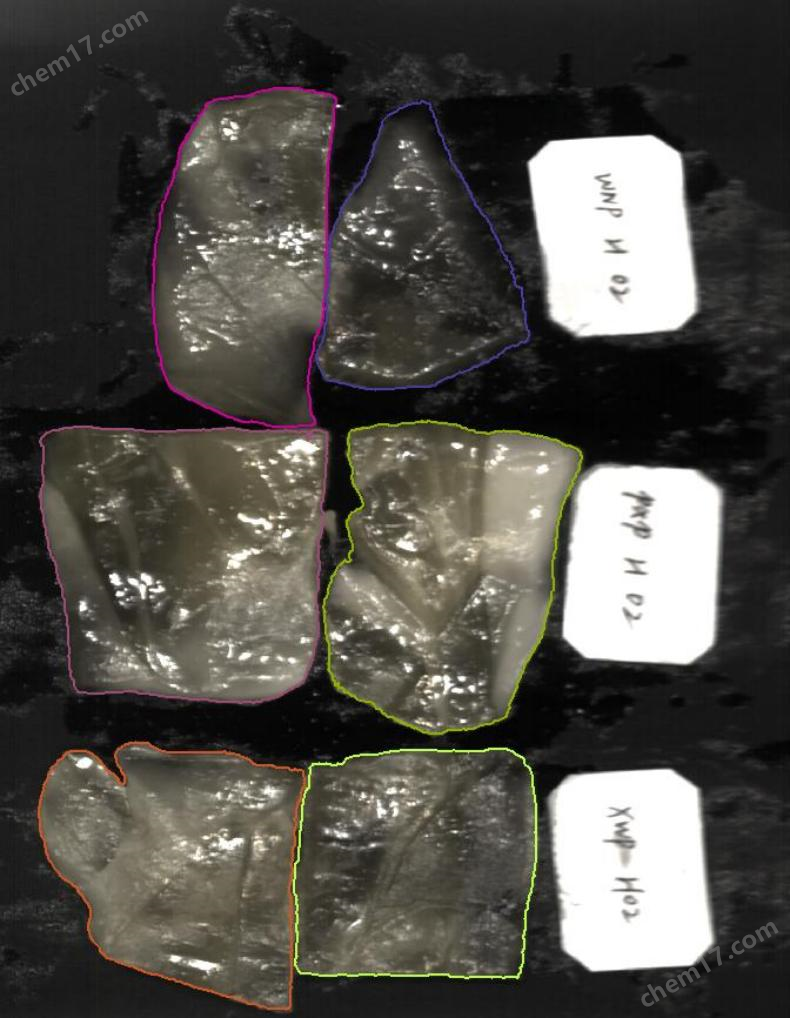
混 03 |
|
混 04 |
|


预处理算法
Savitzky-Golay 滤波: 减小噪声影响
一阶导数: 放大差异, 减轻信号偏移
PCA
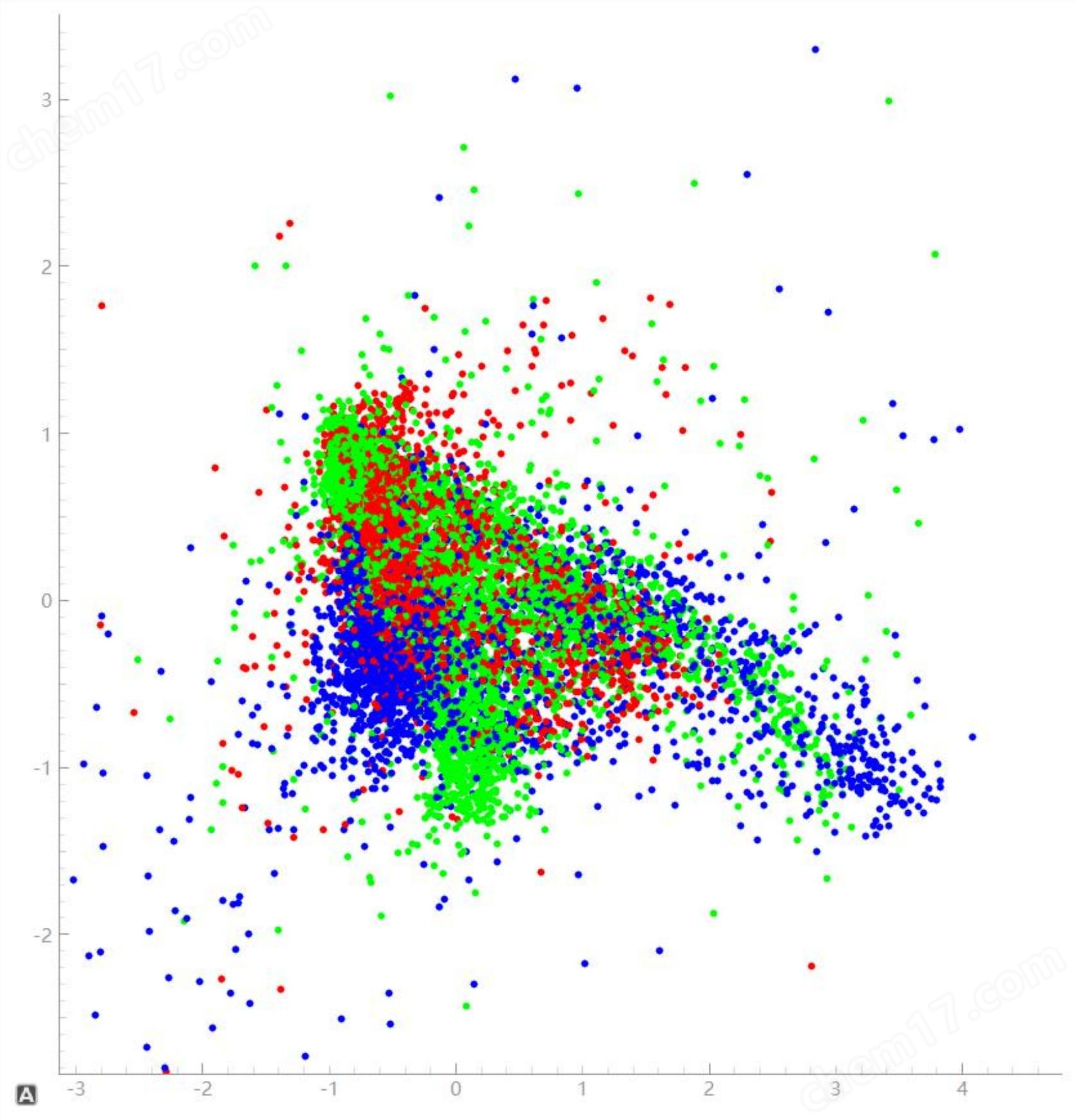
数据划分
训练集 | 混 01(90%), 混 02(90%), 混 03(90%) |
验证集 | 混 01(10%), 混 02(10%), 混 03(10%) |
测试集 | 混 04 |
训练过程
超参数选择
. epoch = 10
. lr = 8e-5
. batch size = 1024
损失和验证集准确率

模型验证
使用未参与训练的光谱文件 "混 04", 验证模型效果
左侧为标注数据, 右侧为模型推理数据, 准确率在 97.3%
使用训练数据集建模
训练数据集打标
训练集数据预处理
训练模型
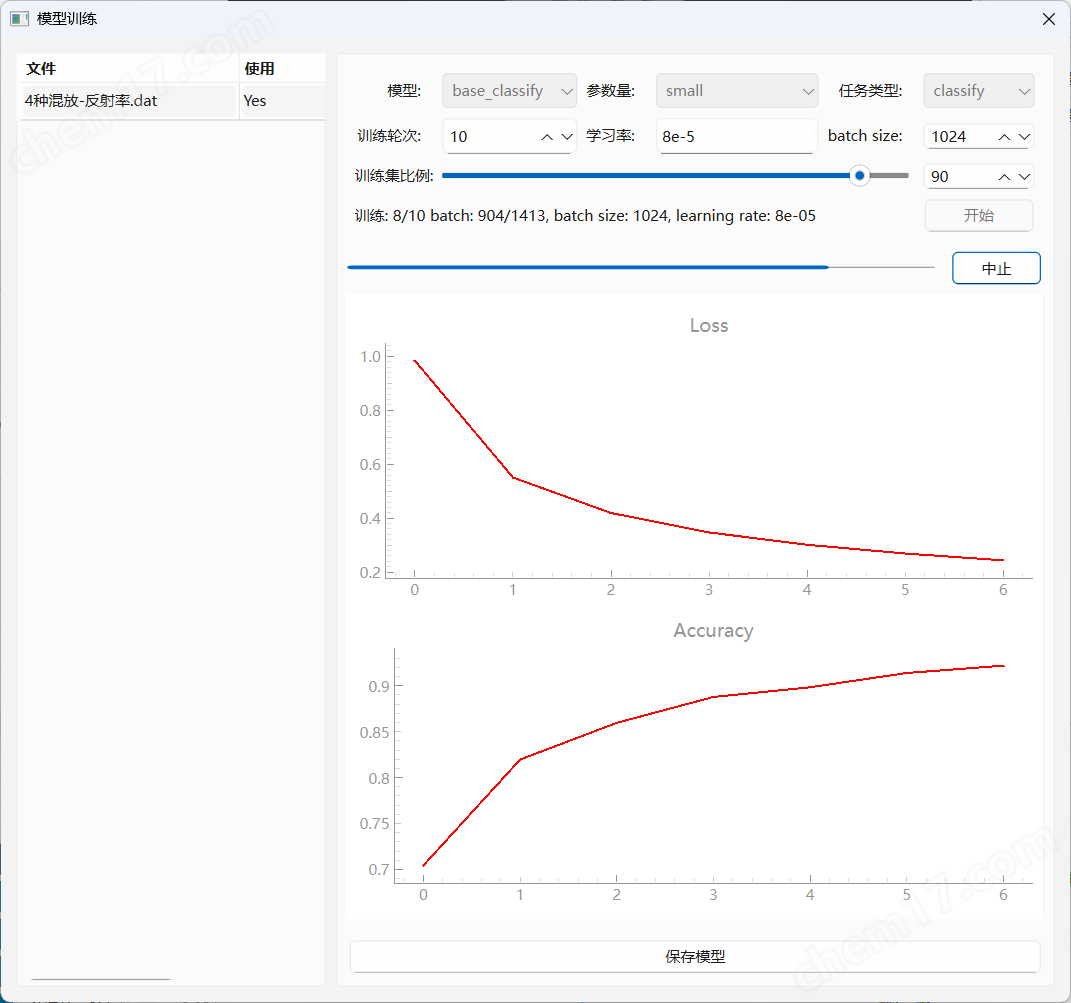
模型训练完成后保存
先使用训练集做模型准确率验证
准确率达到98%

验证模型准确率
使用验证数据集1进行验证
对验证数据集1打标
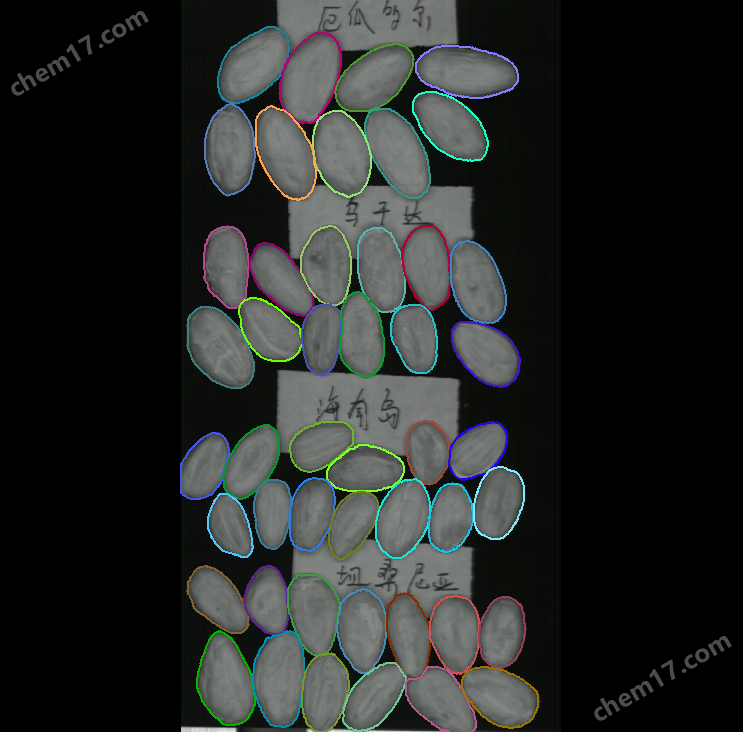
下面右图为提前拍好的每克可可豆的编号,一个编号对应一个产地,
分别为:1-厄瓜多尔;2-乌干达;3-海南岛;4-塔桑尼亚


验证数据集1验证
准确率达82%

使用验证数据集2进行验证
对验证数据集2打标


验证数据集2验证
准确率达84%
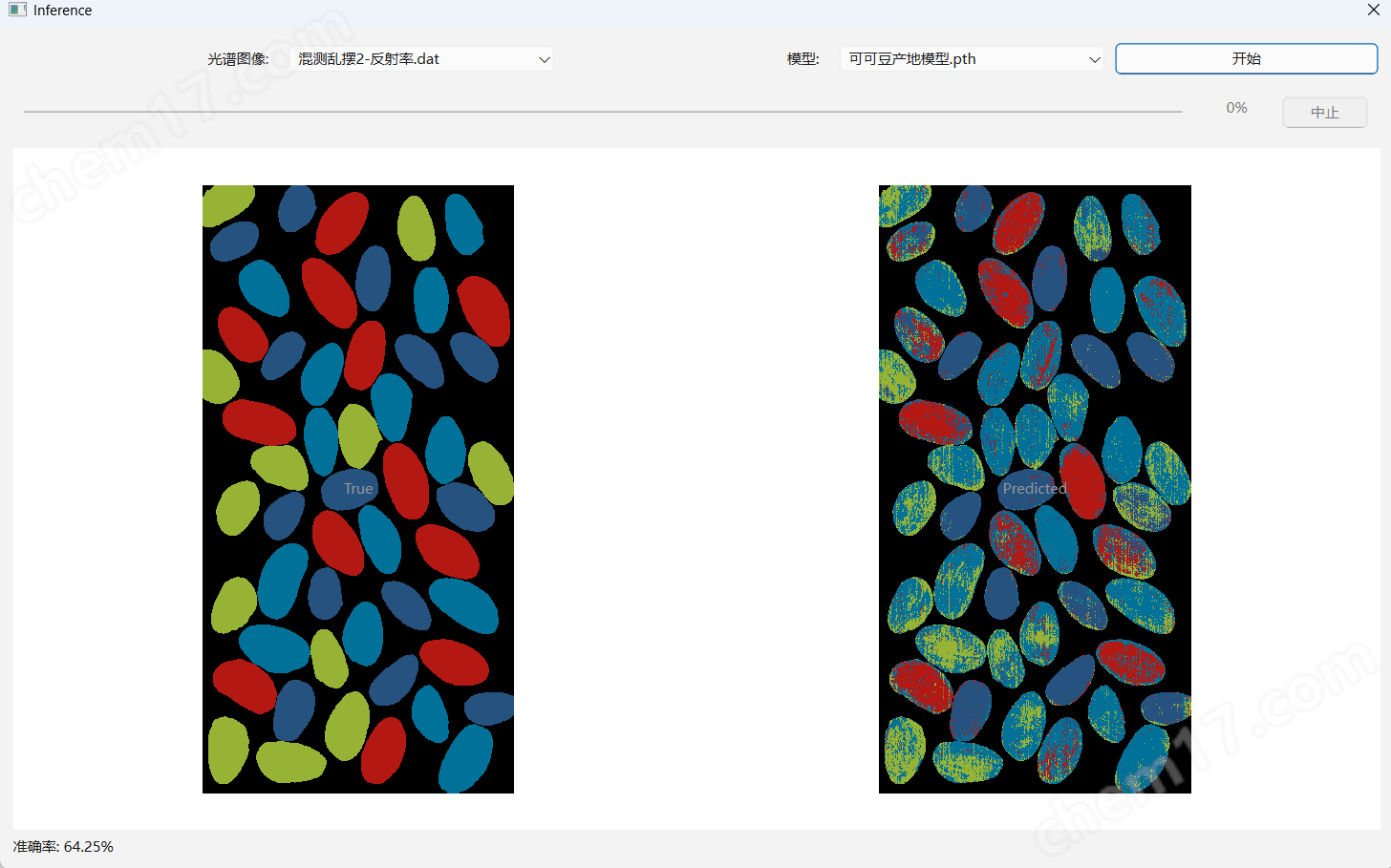
根据验证数据集1和2的验证结果,现有模型的识别准确率可以达到80%。
由于目前的训练集数据较少,准确率不是很高,若训练集数据足够多,模型准确率会更高一些。

 首页
首页
 数据采集
数据采集
 数据处理
数据处理
 联系我们
联系我们